
DataTune 2026
I attended my first DataTune Conf this weekend, right here in Nashville. While data science isn’t my day-to-day work, it’s the reason DataCamp exists and the data science groups are a large part of the local tech community. Plus, I see a future where engineering, data, and product have significantly more crossover. Of course, that future includes AI and I wanted to learn how it was affecting the data science community in comparison with software engineering.
The overall experience was slightly different for me, because I co-organize a local meetup group (Artificial Intelligencers) and because my partner was coordinating the volunteers for the day. So, I got invited to the hockey game and was able to help out a little bit in the mornings with guiding people to the event. Otherwise, I was a normal attendee and the deets I’m sharing are mostly around that experience.
The event is coordinated by a small army of local folks, including the organizers, students, and other wonderful folks in the community. It also has the support of some great sponsors, which helped ensure everyone was fell fed (and had the option for imbibing). Thank you to all of the sponsors, with an extra special shoutout to Oracle for the Assembly Hall gift cards. They’re growing in Nashville, with plans for a beautiful campus in the not too distant future.
If I had to share a couple of key themes from all of the presentations and conversations that I experienced, it’s these:
There is a struggle between technology and adoption when it comes to AI. For things that “just work”, it’s that the technology is here and people are adopting it. For the things that are challenging, it seems to be one or the other is lagging. Sometimes, the technology is here but governance or something else is holding up adoption. For others, the desire for adoption is here, but the technology isn’t ready.
The recent releases of 4.6 and 5.3 were a significant shift. It was mentioned dozens of times that these new models are the first indicator of a significant drop in friction and growth in trust of the capabilities of LLMs.
Get excited. Things are changing and it’s scary, but they’re changing either way. Find your happy place in the change.
Workshop Day

Mastering AI Strategy and Agentic Workflows
Charlie Apigian, Chief Data Strategist at Data Inspire
I chose the combo of workshop and community day, and picked this workshop by Charlie Apigian. He’s a dedicated member of the local tech community and has moved from academia to full-time consulting over the past few years. I’m inspired by both his personal and technical skills and this workshop was right up my alley.
However, it was different than what I expected, in some positive ways. When I read AI Strategy, I quickly assumed that was around implementation strategy. Charlie had a different opinion. He made us (well, strongly recommended that we) sit and think about what’s important to us, express our concerns and curiosities, and create a personal AI mission statement. There’s a good amount of thinking to get to this answer, but I think it’s a great thing to write down.
I use AI as a [ ], to help me [ ], but I will always [ ]
I have a ton of notes from this workshop and it was fantastic. However, I’m not going to pop them all in here. I have one little section that I think summarizes both the workshop and Charlie’s advice:
Take the complex, make it simple. Think strategically. Just start doing it.
If you’re trying to figure out how AI can work for you or your business, I highly recommend grabbing his book: AI Reimagined.
I will share the things I left needing to check out afterwards:
- Claude extension in Chrome
- Blackbird Studio in Nashville
- Plaude device for notetaking
- Acquired Podcast
- Duping my voice in Elevenlabs
- Granola recipes (the app, not the grain)
- Context 7
- Buy Back Your Time: Get Unstuck, Reclaim Your Freedom, and Build Your Empire
Quick Aside
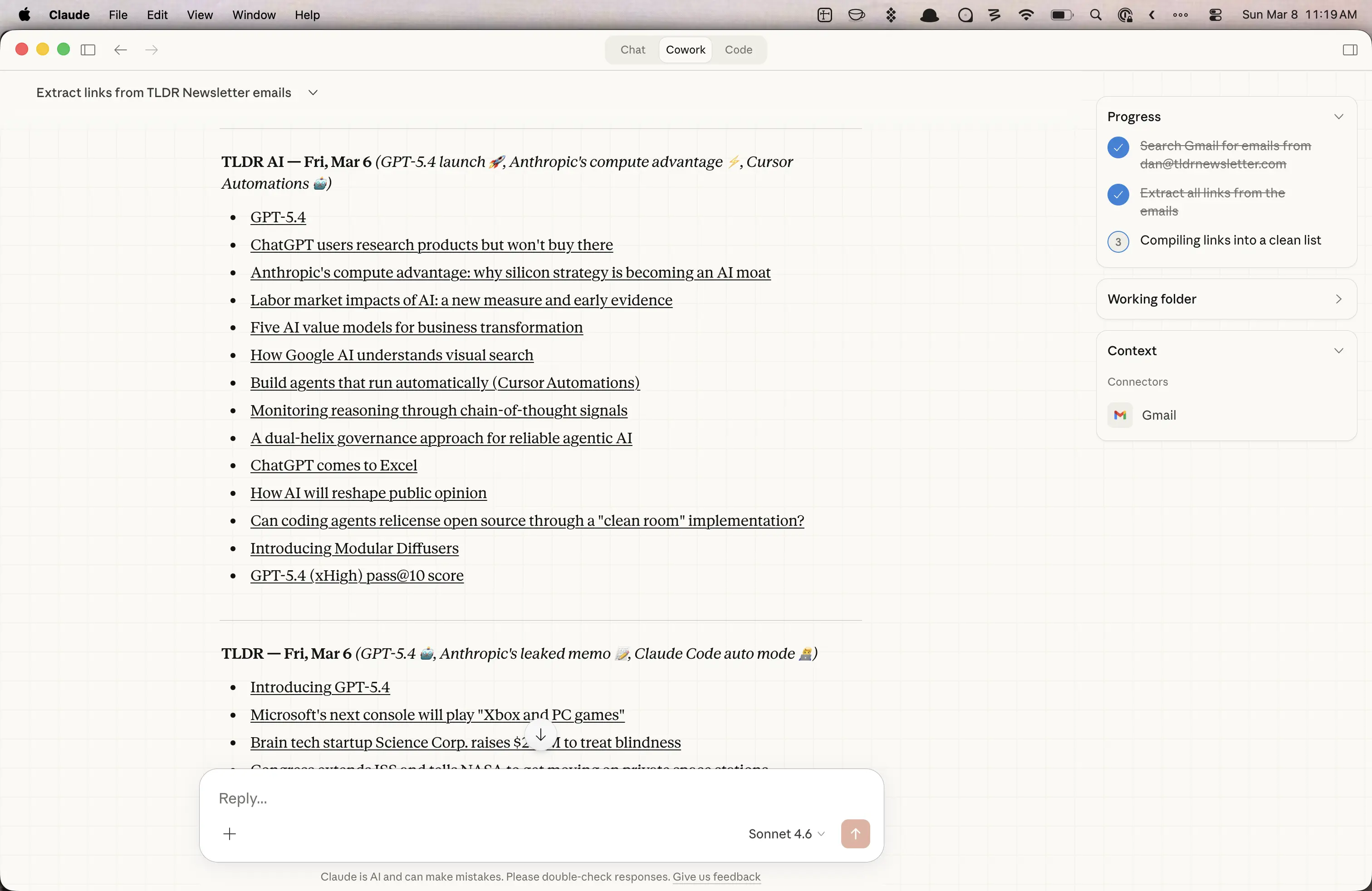
As we were coming up with ideas and chatting about tools, it came to me that I could use Cowork for getting links from email newsletters. It’s one thing I spend a little too much time doing, but that I don’t trust a bot to do for me (or to autonomously connect to my email). So, I have set up a test to do a few emails that I only scan for links. Others often have a nice prompt suggestion or maybe a little content that I want to read, but I’m going to reduce my overall time with the ones that I only scan.
Community Day

From Raw Data to AI-Powered Insights: An End-to-End Journey with Snowflake
Clay Chaffins
I happened to meet Clay at the hockey game and in the usual “what do you do, where are you from” stuff we learned that we each moved to NYC within a month of each other in 2019 and lived a few blocks from each other. It’s a small world, after all. So, I had to check out his talk and I was curious because we teach Snowflake at DataCamp, but I have never touched it.
One of the first things I learned was an expansion on the “medallion architecture” for data. This had been shared in the workshop, but I didn’t ask for clarification. It was really interesting to see a live demo stepping through the various levels of data classification and how queries shift based on what’s available.
I left wanting to try it out. His base demo was using some Nashville music data and I’m going to do something that uses billboard data. (One really cool feature is that you don’t have to bring data, they have a new tool for generative data as well.)
My follow-ups from this one are:
- What public data should I try? Or, what could I learn from my Notion data?
- Is there DataCamp data that I could try?
- How does token reselling work? Snowflake is one of the dozens that offers a pseudo currency of tokens that are used from the frontier models. Are all these companies reselling tokens from a reduced rate or using them from a pool that they pay for?

Not Your Models, Not Your Data? Private Local AI for the Cautious Data Practitioner
Ram Singh
Ram and I run Artificial Intelligencers and so we’ve had tons of talks around this. However, it was excellent to get to see him pitch it in his style, with some simple illustrations that allowed him to talk through complicated systems. Because I was familiar with it, I was also able to scan the crowd a bit and he had people truly interested.
A couple of really nice points that hadn’t made it into prior conversations was that LLMs “aren’t an Oracle Database”. You’re not going to query them and get the same results all of the time. Another was that when you are basing your business on frontier models, you are having to tune at the cadence of the vendors.
One of the strongest pitches for local models is that the major companies right now are subsidizing tokens for growth and learning. This will change, much like his example of Uber pricing in areas that they have outgrown taxis.
My follow-ups from this one are:
- Try a local model on my old MBP or my gaming PC
- Use huggingface, which I surprisingly have not done anything with yet
- Check out exo-explore/exo
- Start with LM Studio (or go right to Ollama)
AI Vibing with Fellow Builders
Group Discussion
The team tried something new this year, with themed discussions during the blocks. Ram and I hosted one for vibe coding with AI, but it shifted more towards a general discussion about how this is currently impacting roles and what the future is. The group was most split on what will happen to software engineering as a role.
Some things that got shared for vibing were a Mac app for taking what’s in your clipboard and turning it into a reusable bit of info for posts on various social media, a custom ERD app that allows for companies to include their internal docs that impact the flows, and The Bot Abides.
My biggest takeaways were from Ryan, who runs ReliaStaff. There are significant shifts in what companies are looking for and a lot of software engineers are limiting their potential for interviews based on not including data or AI related work. There was pushback on that, in that there’s a limited amount of people that could show real work yet. However, he said that companies are looking for people who love this stuff and who are showing it.

Adapt or Be Automated: Continuous Learning in the Age of AI and Data Engineering
Chris Gambill
Today is about the strategy of survival
That quote strongly defines this session. I was fortunate to meet Chris on the bus ride home from the Putt Shack party and we had a good chat. It got even better as he shared his long run of experience and his pragmatic view on how to evolve as the technology is. I saw so many parallels between data work and software engineering in his examples.
Some interesting things that I picked up were: the Gartner Hype Cycle Curve, I vs. T vs. Pi vs. Comb shaped skills, and a good reminder that the old things still win. The best example here was the the principles in software methodology still apply and are often the best things to use when guiding AI.
There were some fantastic questions and one that will likely keep coming up: as code shifts to AI, do all roles shift to a single focus or responsibility? For example, do the various roles in data now shift to people focused solely on the relationship between the business and the customer?
One anecdote: an attendee’s daughter is attending Bama and they have encouraged students to use AI, but with a requirement. You can use it to complete your work, but you have to share what model you used and why. This feels like The Way to be teaching students.
My takeaway from this:
- Apply the 5 hour rule. Chris suggested giving new tools up to 5 hours to dive in and learn. I love this as an example, since the world feels like a firehose right now. I think timeboxing specific things will allow me to dive in with limits.

Structured Meets Generative: The Future of Reliable AI in Healthcare
Armelle Le Guelte
“Would you trust a solution that is sometimes wrong with medical data?” This was a great way to define the problem at hand: speeding up medical data processing, but with no hallucinations.
This was an excellent presentation, both in the technical outlines and the demo of the solution. I think Armelle’s example of how token estimation works is one of the best I’ve seen. I’ve seen many people explain that tokens are primarily trying to predict the next word, but her example for this sentence made it super clear.
The capital of Paris is:
- Paris - 90%
- Dense - 2.4%
- Diverse - 1.2%
- Home - 0.8%
On top of this, I learned so much on the merits of LLMs plus a knowledge graph and she reinforced the challenges with RAG systems and chunking.
My follow-up from this one is:
- Try creating something in Neo4j
- Try creating something with a knowledge graph and real data. Maybe this could be a continuation of my Snowflake project, where I ensure that there are no hallucinations with the music chart data
After Party
After all the talks, there was a nice round of thank yous, some raffles for some dope prizes, and then we were headed off to Fifth and Broadway. It was great to get to wrap up the event with some great conversations.
Thank You
I’m super thankful to the whole team for putting this on, the speakers who give up their time to prepare and deliver presentations, and all of the folks who took their Saturday to share knowledge. I’m already looking forward to next year.
Also, I’m thankful to DataCamp. We have a very generous budget for professional development and it’s so nice to be able to just instantly buy tickets for conferences. I feel very lucky.